GeoNet Challenge Details
ICCV 2023
The primary objective of the 1st GeoNet challenge is to encourage participants to put forth their ideas and algorithms aimed at addressing the issue of geographical bias by utilizing our recently introduced dataset, GeoNet. The competition consists of three different challenges, each focusing on different settings popular in modern domain adaptation. The unsupervised domain adaptation will be conducted on GeoPlaces and GeoImnet, while the universal domain adaptation will be held on GeoUniDA datasets.
[08/21] We released the test set to the registered participants, and the evaluation portal is live now! Link to the challenge leaderboard. Register for the challenge to recieve the test set.
[07/21] Please register for the challenge at this link: https://forms.gle/zSZA1iaPD3mZxjyn7. Note that registering your team is mandatory to participate in the challenge and obtain the test data.
[06/21] Link to the challenge page.
Overview of GeoNet dataset
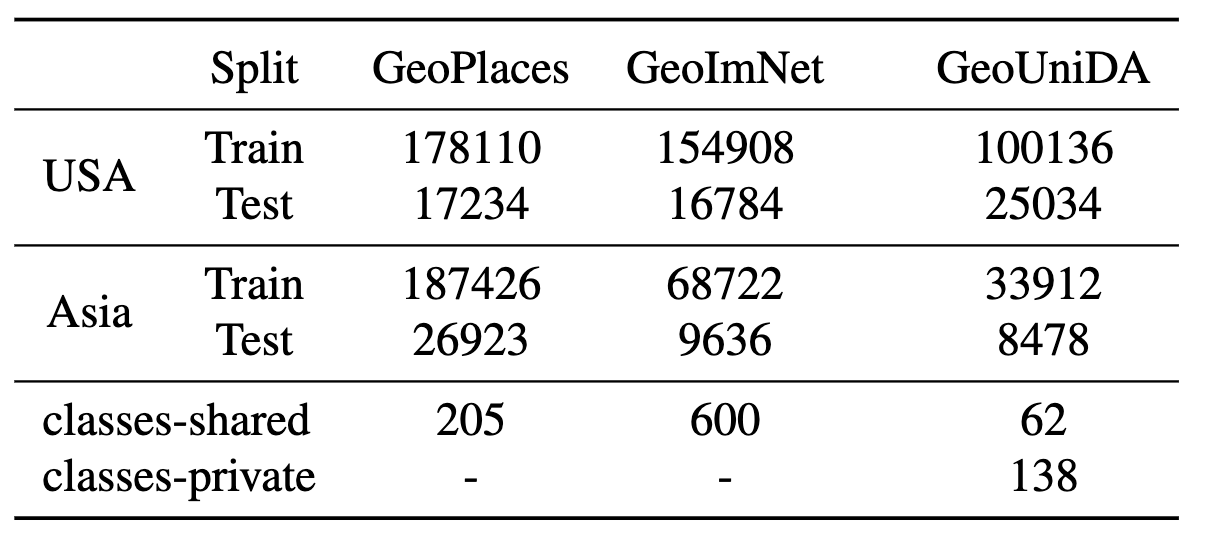
To address the need of evaluating geographical robustness of vision models, we recently created a large-scale dataset called GeoNet which contains images from US and Asia domains covering the tasks of scene recognition (GeoPlaces) and object recognition (GeoImnet). A key facet of this dataset is the cross-geography domain shifts, along with prominent label noise in the training data. Please refer to our CVPR 2023 paper for more details about our dataset. We envision GeoNet to provide a suitable testbed for the community to enable development of geographically robust learning algorithms. Furthermore, we also aim to spur discussion on fairness and inclusivity from the perspective of under-represented geographies. All the participants should use data only from GeoNet for the challenge.
Downloading the Data and Baselines
You can download the dataset here . The code for training baseline models on GeoNet is available at this link.
Metadata Policy: GeoNet also has rich metadata in the form of captions, tags and GPS coordinates for each image available along with the images. Participants may choose to additionally use this metadata for building their algorithms. However, note that no metadata will be provided along with the test set, so the model can only take image inputs at test-time.
Registration Link: https://forms.gle/zSZA1iaPD3mZxjyn7.
Challenge Details
- Unsupervised Domain Adaptation (UDA) on GeoPlaces: In this challenge, the participants have to devise novel unsupervised domain adaptation methods for improving performance on the task of place recognition across geographies. For the purpose of this challenge, the source domain is fixed as USA and the target as Asia domains. Therefore, the task is to leverage the labeled images from the USA split from the GeoPlaces dataset and improve performance on the Asia images, from which several unlabeled images are also provided. The participants cannot use the labels from the Asia images during training.
- Unsupervised Domain Adaptation (UDA) on GeoImNet: In this challenge, the participants have to devise novel unsupervised domain adaptation methods for improving performance on the task of image classification across geographies, where the categories span several objects, places, living organisms etc. For the purpose of this challenge, the source domain is fixed as USA and the target as Asia domains. As with UDA on GeoPlaces, the task is to leverage the labeled images from the USA split from the GeoImnet dataset and improve performance on the Asia images, from which unlabeled images would be provided. The participants cannot use the labels from the Asia images during training.
- Universal Domain Adaptation (UniDA): Universal Domain Adaptation (UniDA) facilitates domain adaptation between source and target domains that have few private classes, in addition to shared classes which are common to both.
In this challenge, participants will have to use labeled data from a labeled USA domain as the source, and unlabeled Asia domain as the target, with an additional challenge that the label spaces do not completely overlap during training and testing.
- Evaluation Metrics: For the UDA challenges on GeoPlaces and GeoImnet, the models will be ranked based on the average Top-3 accuracy on unseen test set from respective tasks. Owing to the label noise and possible equivalent labels in the dataset, we are using Top-3 accuracy and not Top-1 accuracy for this challenge. For the GeoUniDA challenge, following prior work in OpenSet-DA, we use H-acc metric to rank the models for the UniDA task. The H-acc metric is the harmonic mean of the closet-set accuracy (over the seen classes) and the binary open-set accuracy (of rejecting the outlier target test-samples). The H-acc will be evaluated on the unseen test set.
-
Challenge Timeline:
Challenge Data Released June 15, 2023 Challenge Test Set Released August 10August 22, 2023Submission Portal Open Aug 15August 22, 2023 (Link)Challenge Submission Deadline Aug 25September 5, 2023Workshop Date Oct 2, 2023 (Day 1 of ICCV 2023)
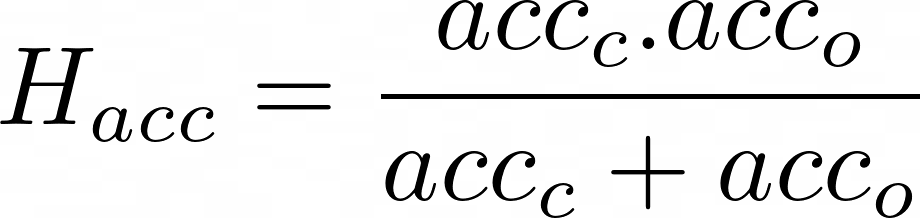
General Guidelines
Registration:
- All the teams have to be registered at this link: https://forms.gle/zSZA1iaPD3mZxjyn7. Registering your team is mandatory to participate in the challenge and obtain the test data.
Model Sizes and Data Policy:
- Participants can only utilize data from ImageNet-1k for pre-training their models and the provided GeoNet data during training and adaptation. Use of any other kinds of external data, either for pre-training or fine-tuning, is strictly prohibited, which includes the collection or annotation of new data related to the target geographies. If you need any clarifications, please feel free to contact the organizers.
- The participants of the challenge can only use the training data from the source domain to train the model. Further, only the unlabeled data from the target train split is to be used during adaptation, and they are not allowed to use any kind of data from the test split. The test split data is provided only to guage/estimate the performance of the trained models.
- The participants are allowed to use the metadata (except the labels!) provided along with the GeoNet dataset. However, no metadata beyond the raw images will be provided at test-time to evaluate the models, so the methods should be designed so as to take only image inputs during testing.
- Since this is an unsupervised adaptation challenge, any method that make use of target labels for training their methods will be automatically disqualified from the competition. Only source labels are allowed for use in training, while unlabeled data can be leveraged from target.
- To ensure fairness across various resource and compute capabilities, we restrict the models to have a maximum of 300 million parameters in total. This is to help encourage methods that design novel algorithmic solutions as opposed to solely relying on scaling up training with larger models. If ensemble models are used, then the total number of parameters in all of the models should not exceed 300M.
- If your method uses a pre-trained image generative model as part of the algorithm, then the parameters of the generative model will also be counted towards the 300M limit. In case of multi-modal models like CLIP, the parameters from both the vision and language encoders will be counted towards the 300M limit. Note that both the generative model or the CLIP-like models cannot be trained/pre-trained on any additional data apart from ImageNet-1k or provided GeoNet dataset.
Winners and Reproduciblity:
- Each team is allowed a maximum of 3 submissions to the leaderboard for the duration of the challenge.
- The winners will be selected based on the leaderboard performance, with separate winners for the three challenge tracks.
- The winners of the challenge will be invited to present their winning solution during the workshop. Additionally, they will also be required to submit a brief report summarizing their solution, as well as a working code and trained models that ensure reproduciblity. If the reproduced results do not match those on the leaderboard, the team will be contacted for further clarifications.
Leaderboard and Prizes!
- Prizes: The total prize money for the challenge would be 9000 USD, split equally between the three challenges. The winner of each challenge will recieve a prize money of 2000 USD, while the runner-up gets 1000 USD. The first and second prize winners from each challenge will be decided based on the leaderboard rankings on the unseen test set.
- Leaderboard: The evaluation portal and the leaderboard is available on EvalAI (link) . Please note the instructions on the submission portal carefully before uploading your prediction files! Registration for the challenge is mandatory to recieve the test set and upload the predictions.
Contact
For any questions or clarifications about the challenge, please contact the organizers at geonet *dot* robustness *at* gmail.com.